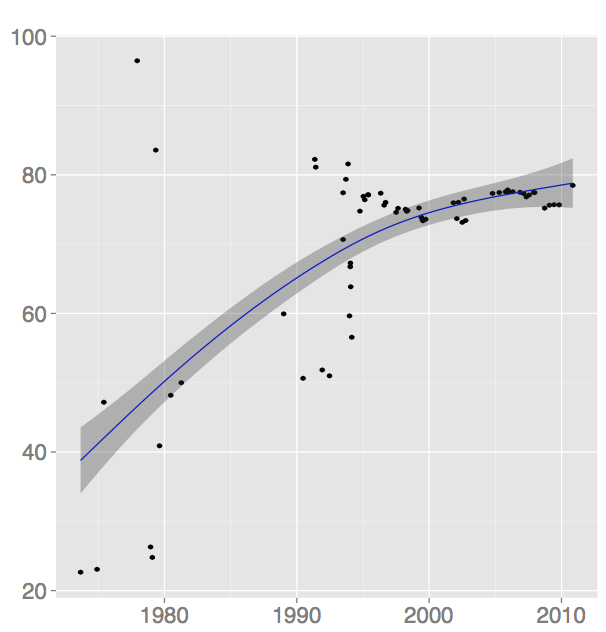
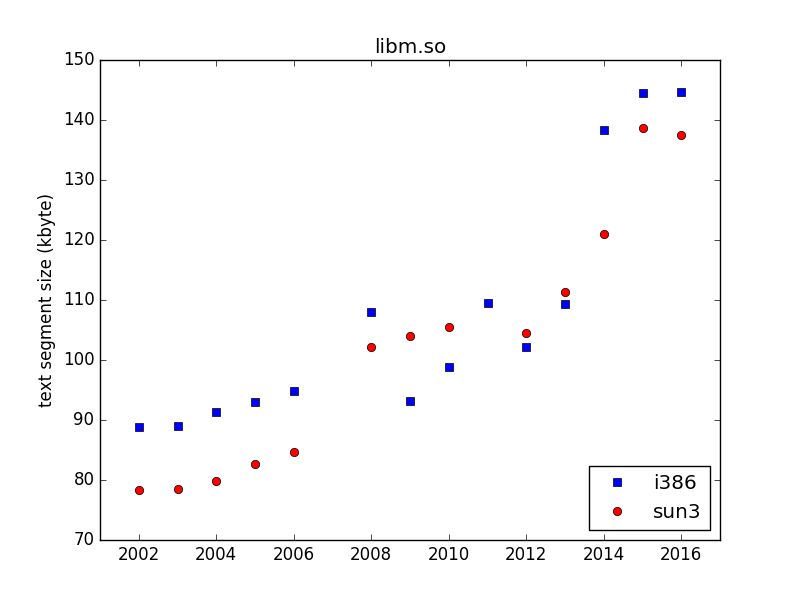
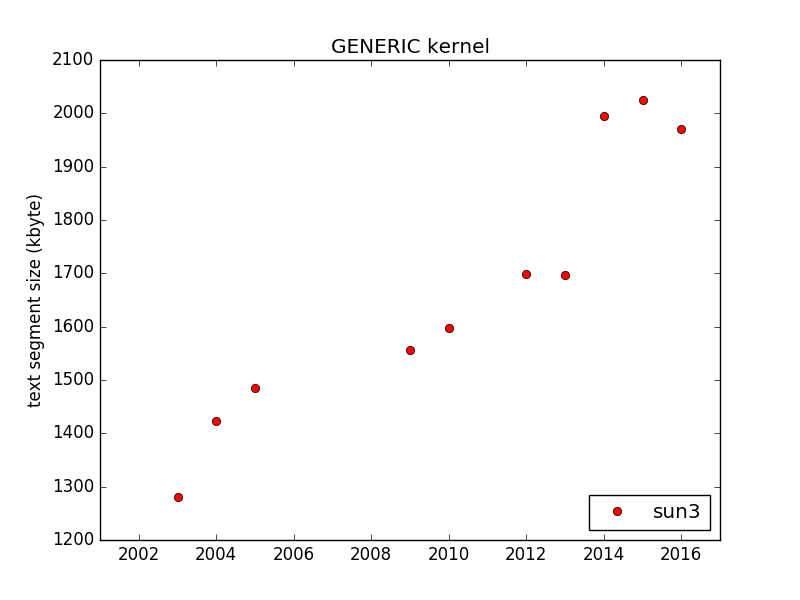
I wrote in an earlier blog post that GCC has a somewhat aggressive interpretation of the standard so that it compiles
p == q to false if p and q are pointers derived from different objects. I'm now convinced GCC is wrong.The problem
C does not permit pointers to point at any memory — a pointer must point to an address within an object or on the address immediately following the object, and pointer arithmetic cannot make it point outside that range. When comparing pointers, the C standard says (emphasis added)
Two pointers compare equal if and only if both are null pointers, both are pointers to the same object (including a pointer to an object and a subobject at its beginning) or function, both are pointers to one past the last element of the same array object, or one is a pointer to one past the end of one array object and the other is a pointer to the start of a different array object that happens to immediately follow the first array object in the address space.That is, the comparison in the
printf call#include <stdio.h> int main(void) { int x[4], y[4]; int *p = &x[4]; int *q = &y[0]; printf("%p %p %d\n", (void*)p, (void*)q, p == q); return 0; }evaluates to true if the compiler happens to place
y directly after x in memory. GCC does, however, substitute address comparison to false if the pointers are derived from different objects, and the program above may give output such as0x7fff66339290 0x7fff66339290 0where the comparison evaluates to false even though both pointers are the same. The argument in bug 61502 is essentially that the standard is unclear what "immediately follow" means, and applications cannot rely on memory layout anyway (so there is no real use case). I believe both are wrong.
Use case
One use case for this kind of comparison in firmware for small embedded devices — you have a framework that supports different hardware configurations, but you want to avoid adding an
C does not have a convenient way of representing the
This particular use case seems to work now as a side-effect by the "missing" optimization of global constant addresses, so the nasty workaround is not needed. But some GCC developers still claim the code is invalid...
#ifdef for every optional functionality. Instead, each implemented functionality exports a structure containing configuration data, and the linker collects them into an address range and generates a symbol __start for the start address, and __end for the address immediately following the array. The good thing about this is that the array contains exactly what is present at link time — elements are added to the array by just adding files to the link command, and functionality can be included/excluded by just relinking, without any need for additional configuration.C does not have a convenient way of representing the
__end label, so it is typically expressed asextern struct my_struct __start[]; extern struct my_struct __end[];where the linker guarantees that
__end is immediately following __start. The array is processed asvoid foo(void) { for (struct my_struct *x = __start; x != __end; x++) do_something(x); }which is compiled to an infinite loop if GCC optimizes comparisons of pointers derived from two objects as always being different. The workaround suggested in the GCC mailing lists is to insert some inline assembly to confuse the compiler
void foo(void) { struct my_struct *x = __start; struct my_struct *y = __end; asm("":"+r"(x)); asm("":"+r"(y)); for (; x != y; x++) do_something(x); }but this should not be needed for the natural reading of the standard excerpt quoted above.
This particular use case seems to work now as a side-effect by the "missing" optimization of global constant addresses, so the nasty workaround is not needed. But some GCC developers still claim the code is invalid...
The meaning of "following"
Comment #3 of the bug report argues that GCC is correct:
Except within a larger object, I'm not aware of any reason the cases of two objects following or not following each other in memory must be mutually exclusive. (If the implementation can track the origins of bit-patterns and where copies of those bit-patterns have got to, it might have a compacting garbage collector that relocates objects and changes what's adjacent to what, for example — I think such implementations are within the scope of what the C standard is intended to support. Or if you're concerned about how this changes bit-patterns of pointers, imagine that a C pointer is a (object key, offset) pair, and that comparison first converts the C pointer into a hardware address, where it's the mapping from object keys to hardware addresses that changes as a result of garbage collection rather than anything about the representation of the pointer.)I do not think this is a correct interpretation. For example, DR #077 asks the question "Is the address of an object constant throughout its lifetime?", and the committee answers (emphasis added)
The C Standard does not explicitly state that the address of an object remains constant throughout the life of the object. That this is the intent of the Committee can be inferred from the fact that an address constant is considered to be a constant expression. The framers of the C Standard considered that it was so obvious that addresses should remain constant that they neglected to craft words to that effect.That is, compacting garbage collection is not within the scope of what the C standard supports. I'm even less convinced by the key/offset example — this is the same situation as "normal" hardware, as you can view the virtual address as a pair (page, offset), and it is still the case that
x[16] is immediately following x[15] for an arrayuint32_t x[32];even if
x crosses a page boundary so that x[15] and x[16] are placed on different pages.